Introduction
Disclaimer: This book aims to analyze the purposes and properties of Blockchain technologies from an engineering point of view, without so much as requiring a technical IT background. This book is for you if you are interested in understanding the formalities of Blockchain, even if you are a beginner. While some exercises will be given in the Rust programming language, these can be skipped entirely.
By the end of this book, you should have an in-depth understanding of the techniques and processes that come together to create a Blockchain network and, if you followed the Rust exercises, have created one yourself.
...
A blockchain is essentially a distributed system of consensus. In simpler terms, you can view a blockchain as a network of machines, all coming together to agree on a decision. This is complicated, because different machines might have a different view of same the network. Consider the following example:
High-school marble problem
Alice (A), Bob (B) and Christie (C) are each a different machine in our blockchain network. Let's imagine they are all players in a high school game of marbles. A, B and C each own a unique set of marbles. These marbles can be created, traded, or even destroyed!
- A, B and C are different players.
- Each players owns a unique set of marbles.
- Marbles can be created, traded or even destroyed.
Decentralized marble game
In the real (physical) world, it would be trivial to know how much marbles each individual has, and which marbles these are: you would only have to count them. However, in the virtual cypherspace of cryptocurrencies, this isn't as easy: there isn't a centralized point where we can view all of the marbles. Similarly, we can't rely on a single individual to tell us the truth: what if they lied!
Blockchains resolve this problem in a variety of ways by allowing us to ensure, with either absolute certainty or a very high probability of certainty, that each player is telling the truth.
In the following chapters, we will be discussing practical solutions to the problems posed in this decentralized marble game, namely:
- How to ensure each player is telling the truth.
- How to punish bad behavior.
- How to safeguard the logical continuation of the network (here, the game).
But first, I would like to start with a brief history of the web and why these kinds of decentralized technologies are even needed in the first place.
Acknowledgments
This book is largely based on the lectures of Joshy Orndorff during wave 5 of the Polkadot Blockchain Academy in Singapore. You can find him on twitter at @joshyorndorff.
About the author & conflicts of interest
I am a graduate of the Polkadot Blockchain Academy, or PBA, which was hosted and paid for by the Polkadot treasury. I have prior experience in writing Blockchain Node software for the Starknet ecosystem.
This book might receive funding from external sources and if that is the case, it will be made explicit. This book does not aim to endorse or condone Polkadot or any other blockchain (such as Ethereum or Bitcoin) but where relevant might point out perceived advantages / disadvantages in technology between such networks.
Finally, since this book is written from the perspective of one more familiar with Polkadot and Ethereum, it will naturally touch more on aspects of these networks as compared to others.
A Brief History of Information
Blockchain technologies can be seen as a continuation of Humanity's history of shared storytelling: they are a way to mathematically come to consensus in a narrative, which allows us to share that story between multiple parties without it being changed.
consensus: a state where multiple parties come to an agreement.
ex: How many marbles does Alice have? Alice says 3, Bob says 3 and Christie says 3. Alice, Bob and Christie have reached consensus.
Blockchain differs from typical methods of consensus which are vulnerable to degradation over time through word of mouth. Even written stories are not absolute and are subject to change through re-writings and translation. With Blockchain technologies, a narrative can1 be absolute and forever fixed throughout time.
Web 1.0
Before Blockchain, and before the modern-day Web, this was the primal state of the internet. At this stage, the notion of a worldwide information network had only begun to dawn, with always-on servers being used for the first time for static information serving.
With this early state of the Web also came a low threat level: bad actors were either uncommon or deemed not a concern. This was about to change however.
Web 2.0
With the Web growing as a utility came the rise of dynamic services such as email and later social media. These are centralized services, with many trust assumptions baked in:
- You must trust the service provider does what you ask it to.
- You must trust the service provider doesn't misuse the information you give it.
- You must trust the service provider acts fairly and not only in it's own self-interest.
However, each of these tenants has been violated time and time again, either because of logical mistakes2 or because it was simply more lucrative3 to do so.
While Blockchain cannot protect us from logical mistakes, it can protect us from such abuses of power as are inherent in a centralized system. This includes most importantly censorship and discrimination.
At the same time as the rise to prominence of dynamic services made the Web much, much more lucrative4, so did the threat level increase substantially, with cyberattacks becoming more prominent5. This is something with which Web 2.0 struggles in particular since services are centralized and most importantly opaque: it is impossible to verify if a service provider is secure enough, you once again have no choice but to trust them.
Web 3.0
The decentralized Web. Built on top of strong cryptographic guarantees, this new Web lays the basis for trustless worldwide services which are not controlled by a centralized entity. Web 3.0 data does not need to make any trust assumptions, meaning it is possible to engineer services where your trust cannot be abused by a central entity: with a well thought-out system, anyone in the world can verify the origin and integrity of the data being served to them.
Web 3.0 is in effect a safer, more democratic successor to Web 2.0.
This new Web is built with the highest adversarial conditions in mind and is even resistant to state-sponsored actors. Web 3.0 can be private, permissionless, final and unstoppable.
The state of Information going forwards
With Web 3.0 currently in its cradling phase, the potential is there for a revolution in the way in which existing systems exchange information. However, this will most likely first be just an evolution on the short -or even long- term as research advances in the field.
Web 3.0 is not a silver bullet. Like any tool in engineering, it offers interesting properties and drawbacks around which we can create new systems and products. Unlike what the hype might want you to think, Web 3.0 is not there to change the world, but rather a specific subset of the world that can benefit from these properties.
It is important to realize that despite it's already considerable financial impact, Web 3.0 is indeed only in it's early stage, and this is a good thing! It means that individual like you and me still have a lot to contribute to this growing ecosystems, with many problems waiting to be solved and business opportunities waiting to be found.
Understand this more as blockchain can reach these properties in a theoretical vacuum, not that any blockchain currently implements these properties to the levels described in this book (some might): this is more of an ideal to strive towards, one we will get to in time but which is currently out of reach for technical reasons. Remember this is still a field of ongoing research!
See the 2017 Equifax data breach and resulting settlement.
As was the case with Cambridge Analytica in 2018.
The Ugly: the pitfalls of Web 3.0
As discussed previously, Web 3.0 is not a silver bullet. While it has many interesting properties that contribute to it being theoretically more secure than Web 2.0, these mathematical security guarantees are by themselves not enough -as we will see here.
Social Vulnerabilities
While Web 3.0 provides safer guarantees in terms of integrity and authenticity of information, it is arguably more vulnerable in it current state to the main type of cyberattack technique used in Web 2.0: social engineering.
social engineering: the manipulation of people into taking actions that compromise their security or privacy.
ex: a common type of social engineering is phishing, where an attacker convinces it's target to click on a malicious link which has unintended consequences such as installing a virus on the target computer or, in the case of cryptocurrencies, draining all the victim's funds.
The reason why Web 3.0 is currently more vulnerable to this type of attack is because of the complexity of the subject at hand: Web 3.0 is fundamentally multidisciplinary, involving advanced topics from economics, cryptography, game theory and other fields still. With most of the world population still crypto-illiterate, this is an easy point of attack for malicious actors, as can be seen in the many scams, ponzis and such which plague the crypto world today.
It can be argued that crypto-literacy is at large the greatest hurdle yet to be overcome by Web 3.0.
Trust is still the Name of the Game
Web 3.0's greatest strength is it's ability to provide trustless ways to execute code (we will examine those more in depth over the course of this book). But what about the code itself? It is important to realize that here again we need to trust the developers who wrote the code:
- We need to trust the code is bug-free, that is to say there is no unknown, unintentional vulnerability.
- We need to trust the code is exploit-free, that is to say there is no hidden, intentional vulnerability.
The DAO attack is one of the most notorious examples of the issues that can arise from blindly trusting code.
On June 17 2016, an unidentified hacker began attacking The DAO, the largest Ethereum DApp (decentralized application) at the time, holding a total of $250 million in assets. They used what is now known as a "re-entrency attack", a then unknown1, unintentional bug in The DAO's code. The attack resulted in one of the most troubled times in Ethereum's history and the creation of Ethereum Classic.
As mentioned before, Blockchain technologies do not protect us from logical errors, and so we are still vulnerable to code exploits such as these. Even worse: nothing stops a malevolent actor from intentionally creating bad code that can later be exploited.
This can be mitigated at the protocol level by allowing anyone to inspect the code of Blockchain applications, but this does not guarantee that a bug or exploit won't be missed2.
Inconsistencies in a Shared Narrative
At the core of Web 3.0 is the notion of shared narrative we discussed before. You can see a Blockchain as a community of people who believe in one such narrative. This is the case of networks like Ethereum or Bitcoin.
Blockchains exist because people come together around the world in unison to interact together according to a common protocol, or set of rules.
What happens however when the rules to a common protocol are broken? This is typically the case during periods of intense community discourse. To continue on the example of The DAO, there was a strong divide in the Ethereum community at the time as to which was the best way to address the hack, or if it should be addressed at all.
Some members of the community believed the attacker had done nothing wrong: indeed, they had only been using the code as it was provided. It was a bit as if a bank had left their vaults out in the open and the bankers had started posting blog posts on how to open it. To punish the thief would go against the principle of immutability of Blockchains: it would be like taking our great shared story, finding a passage we didn't like, and changing it into something else entirely. Now a part of that story is gone forever.
This divide into two camps led to two version of the same Blockchain:
- Ethereum, were the attack had been rolled back. It was as if we had time traveled into the past to stop a bank robbery and that was now our new story.
- Ethereum Classic, where a portion of the community had decided to do nothing in order to preserve what they saw as the core values of Blockchain.
It was as if all of a sudden your favorite character died in a series, and you and a very large group of friends all decided to upkeep you own version of the plot where they kept living: now we have two contending story lines which are battling it out for which is the real one -yikes.
This is what is known as a chain split, and has happened in other chains as well (and again in Ethereum with Ethereum POW).
It is important to realize that despite all its cryptographic guarantees and advanced game theory, Web 3.0 and Blockchain remains before all a social construct, and can be disrupted in periods of social turmoil. This is good because it allows for resistance to unfair change by dissident groups, something that is not so easy in the real world, but at times it can seriously hamper the stability of these networks.
What we can do better: solutions to these issues
What the previous issues highlight above all else is that as much as Web 3.0 and Blockchain are a mathematical problem, they are also a complex social problem involving many different people and diverging points of view.
Ethereum suffered because of this in its early days since it did not have any dedicated way to handle these differences in opinions at the protocol level. In a way, while Ethereum was the story, there was no central meeting point where storytellers could convene to discuss its future and potential amendments to it.
In the real world, we have structures to deal with these issues: governments. But how can we take ideas from existing, centralized structures of governance and implement them in a decentralized way? While we will be focusing on more technical details (Blockchain Governance will be a topic for a future book), keep this idea in the back of your mind as a potential solution.
With this brief introduction to the advantages, drawbacks and challenges of Blockchain, let us now dive into the core subject at hand.
In reality, the exploit had already been brought to the light by various members of the community, with Christian ReitwieBner being the first to discover it and warn the developers behind The DAO, while Peter Vessenes was the first to write a blog post about it less than two weeks before the attack. The bug was deemed of little importance however and even Vitalik at the time tweeted he was not worried by the news and was still buying DAO tokens.
For a long time, it was believed that open-source software -that is to say software where anyone can view and contribute to the code- was impervious to bad actors since anyone could verify the code and point out any malintent or error. Recent exploits such as the notorious xz-utils backdoor have shown however that the complexity of certain projects has grown to the point where it is possible for malicious code to be (very) cleverly concealed in plain sight.
Activity: your first activity
Activities allow you to test you knowledge by practicing what you've learned. These take the form of small Rust projects that slowly build up on each other into something more advanced.
The goal of these is to eventually have you writing you own Blockchain from scratch, and being able to say you did it all yourself!
Starting an activity
You can find the code for activities on github. Create a fork of the repository and cd into the activities folder to complete each set of exercises.
Activities assume you are using the latest stable version of Rust and will provide all needed dependencies. Feel free to add new dependencies as you see fit, just try not to use anything that makes the job too easy for you. All tests will be run locally on your machine so that is not a problem.
A sample activity is provided for you to make sure everything compiles on your machine. Make sure that works before moving on!
Activity 1: Multiple choice quiz
Since the first section of this book has so far been more focused on abstracts concepts surrounding Blockchain, our first activity will not be a hands-on project.
Don't worry, the next activity will be hands on!
#![allow(unused)] fn main() { // TODO: // > What is the main purpose of a Blockchain technologies? // > // > - a) To create digital currencies. // > - b) To replace traditional banking systems. // > - c) To achieve mathematical consensus in a narrative. // > pub fn question_0() -> char { todo!() } // TODO: // > In the context of the high school marble problem, what does "consensus" mean? // > // > - a) When players finish the game. // > - b) When multiple parties come to an agreement on the state of the game. // > - c) When one player convinces others to give up their marbles. // > pub fn question_1() -> char { todo!() } // TODO: // > Which of the following is NOT true about Web 2.0 services? // > // > - a) Web 2.0 is centralized. // > - b) Web 2.0 requires trust in service providers // > - c) Web 2.0 is inherently cryptographically secure. // > pub fn question_2() -> char { todo!() } // TODO: // > What does it mean for Blockchain to be a "continuation of Humanity's history of // > shared storytelling"? // > // > - a) Blockchain is primarily used for writing fiction. // > - b) Blockchain allows for a fixed, unchangeable narrative over time. // > - c) Blockchain is vulnerable to degradation like oral traditions. // > pub fn question_3() -> char { todo!() } // TODO: // > Why is Web 3.0 arguably more democratic than Web 2.0? // > // > - a) It doesn't require trust in centralized entities. // > - b) It allows for direct voting on all decisions. // > - c) It's controlled by elected representatives. // > pub fn question_4() -> char { todo!() } // TODO: // > What is described as potentially the greatest hurdle for Web 3.0 to overcome? // > // > - a) Technical limitations of blockchain technology. // > - b) Government regulations. // > - c) Crypto-literacy of the general population. // > pub fn question_5() -> char { todo!() } // TODO: // > What are some ways to mitigate the risk of code exploits in blockchain // > applications? // > // > - a) By allowing anyone to inspect the code. // > - b) By using only professionally audited code. // > - c) By implementing strict regulations on developers. // > pub fn question_6() -> char { todo!() } // TODO: // > What event is an example of vulnerabilities in trusting code? // > // > - a) The Equifax data breach. // > - b) The Cambridge Analytica scandal. // > - c) The DAO attack. // > pub fn question_7() -> char { todo!() } // TODO: // > In the context of Blockchain, what is a "chain split"? // > // > - a) A method for increasing transaction speed by processing parallel chains. // > - b) A division of the community resulting in two competing versions // > of the blockchain.S // > - c) A way to distribute mining rewards more fairly. // > pub fn question_8() -> char { todo!() } // TODO: // > What is the relationship between Web 3.0's cryptographic guarantees and its // > vulnerability to social engineering? // > // > - a) Cryptographic guarantees make Web 3.0 immune to social engineering. // > - b) Web 3.0 may be more vulnerable to social engineering due to its complexity. // > - c) Web 3.0 is equally as vulnerable to social engineering as Web 2.0. // > pub fn question_9() -> char { todo!() } // TODO: // > What paradox can you highlight regarding the trustless nature of Web 3.0? // > // > - a) Trustless systems require more trust from users. // > - b) The more trustless a system becomes, the less secure it is. // > - c) While transactions are trustless, users still need to trust the developers // > who wrote the code. // > pub fn question_10() -> char { todo!() } // TODO: // > Which is a way to address the issue of diverging opinions in blockchain // > communities? // > // > - a) Exploring decentralized governance structures inspired by real-world // > solutions. // > - b) Implementing centralized control mechanisms. // > - c) Creating immutable rules that can never be changed // > pub fn question_11() -> char { todo!() } }
Checking your answers
- To make sure you haven't made any mistake in the format of your answers:
cargo test
- To make sure your answers are correct:
cargo test --features solutions
P2P networking
Most online services in Web 2.0 follow a simple client-server architecture, where a client (the person using the service) makes a request to a centralized server belonging to the service provider. This centralized server then sends a response to the client which satisfies the initial request.
Facebook is a good example of a client-server model: when you like a post, a request is sent to the Devi- ahem Facebook servers. These in turn register your like and send an updated version of the like count to other users who are seeing the same post.
flowchart LR
C1[Client]
C2[Client]
C3[Client]
S[(fa:fa-server Server)]
C1 --> S
C2 --> S
C3 --> S
S --> C1
S --> C2
S --> C3
Fig. 1: A typical client-server architecture
What happens however if this server was to shut down? We refer to this sort of dependency on a single component as a centralized vulnerability.
Centralized vulnerability occurs when a system relies entirely on one of its components to function: if that component were to stop functioning, it would affect the rest of the system.
ex: Fuel is a centralized vulnerability in a car. If a car runs out of fuel, it stops working. There is no alternative that can take its place.
In the case of our client-server model, this is an issue since it means that any client, or user, trying to connect to a failing server will not be able to use the service it usually provides.1
flowchart LR
classDef serverDown fill:#ff5050,stroke:black,color:black
C1[Client]
C2[Client]
C3[Client]
S[(fa:fa-server Server)]:::serverDown
C1 --x S
C2 --x S
C3 --x S
S ~~~ C1
S ~~~ C2
S ~~~ C3
linkStyle 0 stroke:#ff5050
linkStyle 1 stroke:#ff5050
linkStyle 2 stroke:#ff5050
Fig. 2: Services which rely on client-server architectures are vulnerable to outages
There is an easy solution to this: add more servers! That way if one stops working, another one will be able to take its place. While this might protect us from outages and external malicious attacks, it does not protect us from internal malicious attacks.
Even with multiple redundant servers, there still exists a single entity with absolute power over the service it provides. Nothing prevents that entity from abusing that power by choosing to restrict certain users for example, or censoring content it does not approve of.
Decentralized servers
Pier to Pier networking, or (P2P), describes a network in which there resides no central authority with absolute power over the services it provides.
Some examples of popular P2P networks include Gnutella and Bittorent.2
P2P networks function by allowing anyone to enter as a server, also called a Node. Crucially, every Node should have the same power of influence over the network. That way, there is no centralized point of failure.
flowchart LR
classDef serverDown fill:#ff5050,stroke:black,color:black
C1[Client]
C2[Client]
C3[Client]
U1((fa:fa-user))
U2((fa:fa-user))
U3((fa:fa-user))
S1[(fa:fa-server Node)]
S2[(fa:fa-server Node)]:::serverDown
S3[(fa:fa-server Node)]
S1 --- U1
S2 --- U2
S3 --- U3
C1 --> S1
C2 --x S2
C2 --> S1
C3 --x S2
C3 --> S3
linkStyle 1 stroke:#ff5050
linkStyle 4 stroke:#ff5050
linkStyle 6 stroke:#ff5050
Fig. 3: A typical P2P network
As opposed to the typical client-server model, P2P networks distribute the data and computation they require over every Node in the network, with data being saved in multiple copies. That way, even if a single Node goes offline, another Node can take its place.
As you can see in figure 3, even if a single Node in a P2P network goes down, users can simply connect to another Node to access the service provided by the network. Each node can be individually owned by a unique uperator, with the largest networks boasting millions of Nodes and still no central point of failure.
Drawbacks of P2P networks
1. Speed
Not all P2P networks are necessarily slower than centralized alternatives, and can actually prove to be faster in certain cases. This makes sense if you consider how a P2P network like BitTorrent breaks up the load of storing data across multiple Nodes: instead of a single server storing the entirety of a file, each Node stores only a portion of each file.
This in turn allows us to download multiple parts of a file at once, which can be an advantage for popular files which are available over many different nodes. This kind of situation becomes more complicated for systems with stronger cryptographic guarantees, such as Blockchain, where the cost of computation generally outweighs the advantages of data being available across multiple Nodes in a network.
xychart-beta
title "Blockchain Time To Finality"
x-axis [ "Bitcoin", "Ethereum", "Polkadot", "Solana", "BNB chain", "Avalanche" ]
y-axis "Time To Finality (in seconds)"
bar [ 3600, 960, 60, 12.8, 7.5, 1 ]
line [ 3600, 960, 60, 12.8, 7.5, 1 ]
Fig. 4: Chart of Blockchain Time To Finality. source
Time To Finality, or TTF, is a measure of how long it takes for information to be considered 'valid' on a Blockchain. As you can see in Fig. 4, current Blockchain P2P networks are still a far cry away from the instantaneous response times of centralized systems.
It is possible however to imagine a future where advances in algorithms and hardware have allowed Blockchain technologies to operate on a level comparable or even faster in certain cases than traditional Web 2.0 alternatives. This is already evidenced by networks such as Avalanche or Solana, although whether Solana is a decentralized network as of the time of writing is arguable.
2. Initial adoption
Another issue with these networks is that they are above all social networks. This means that a P2P network lives and dies by its users: unlike a centralized service, there is no corporate entity to pour in large sums of money to pay for server upkeep. If there are no users, and no Nodes, then there is no network. Conversely, the more users a P2P network has, the more effective it becomes.
This is know as the Network Effect, which states that a service gains additional value as more people use it. The inverse is also true, such that a service with a low user count has lower value.
This can be seen as a positive aspect, as P2P services naturally grow or shrink in response to their popularity, but it also means that it can be especially hard for a P2P network to take off in its infancy, when it only has very few Nodes.
3. Legal challenges
Finally, the most glaring issue of P2P networks is their alegality.
Alegality describes a status which is neither legal or illegal, but rather exists outside of the effect of the law, ie: the law has no power over an alegal entity.
While P2P networks might be alegal, the developers creating them most certainly are not, and can be indited, prosecuted and punished by the law.
As a result of the lack of centralized points of failure, P2P networks are especially hard to stop, to the point that given a sufficiently large community this might be impossible. This can make them a safe haven for illegal services, such as piracy, pornography or gambling.
This is significant since historically, the developers or companies behind P2P networks have been held responsible for any illegal activity facilitated by the network they were developing.3 This has especially been the case for copyright infringement.
Be very advised when creating a P2P network that you are essentially building something that will escape your control. You should have taken especially good care you risk no legal responsibility for the activities which take place on the network you are developing, else you risk enjoying a pretty view onto a concrete wall and iron bars for the rest of your life. Consult a lawyer for goodness sake.
When to use a P2P network
In conclusion, while P2P networks have their drawbacks, they offer considerable engineering advantages in terms of resilience and data availability.
At their core, P2P technologies are best suited for use in adversarial situations such as military applications4, censorship resistance, and high bandwidth networks with many worldwide concurrent (simultaneous) request for data.
While the legal implications associated with P2P networks are daunting, they are an extremely useful tool in the fight against centralized points of vulnerability, and probably the only one to be truly effective.
The CloudStrike Blue Screen of Death disaster which took place on the 18th of July 2024 is a perfect example of the dangers than can arise from centralized vulnerability, with an estimated 8.5 million systems affected worldwide as a result of the mistakes of a single company. This was possible due to an auto-update feature in ClowdStrike's Falcon software. While this was arguably a pipeline and testing issue, it also demonstrates the dangers associated in entrusting so much power in a single entity.
Napster might also come to mind, however while it utilized P2P techniques it still relied on a centralized indexing server for retrieving information in the network. While it was still possible for people to set up their own indexing server as was the case during the Metallica debacle, this still meant not all nodes were treated equal, so Napster cannot be considered a 'true' P2P network.
In 2009, popular P2P torrenting website The Pirate Bay faced legal action for aiding in copyright infringement, which ended in its three founders Frederik Neij, Gottfrid Svartholm Warg and Peter Sunde facing 1 year in prison as well as $3.6 million in damages.
The initial Chord paper (which was instrumental in paving the way for modern P2P techniques) in fact received direct funding from DARPA and the Naval Warfare System Center of San Diego.
Identity in P2P networks
P2P networks consist of a decentralized array of servers. These Nodes are arranged around the world and owned by many different individuals. When you want to communicate with someone, you can send them a letter (yes, very archaic): for that you need that person's address, which is a form of identity. Similarly, for the Nodes in a P2P network to be able to communicate between each other, there needs to be a way to identify them.
We cannot rely on existing techniques such as IP addresses, since they need to be recognized by a centralized entity to function. Ideally, we want our P2P network to be able to keep functioning independently of the rest of the web.
As an alternative, each Node issues itself a random number, which acts as a Global Unique Identifier, or GUID. But how is this possible? What if two different Nodes issue themselves the same GUID? This is known as a collision.
A collision in cryptographic terms refers to when a function gives the same output for two different inputs. This is an issue when we need outputs to be unique for identification purposes.
Collisions are generally seen as vulnerabilities and a potential attack vector.
Consider the following example: you and 4 of your friends are playing a guessing game. You each guess a random number between 1 and 4, and whoever manages to choose a unique number first wins. In this game, it is highly likely for there to be collisions in you answers because the space of possible answers is so small.
Now imagine instead that you and your friends can guess any number between 0 and 1 million. The odds of two players guessing the same number becomes very low, to the point where it is negligible (meaning this is so unlikely to happen we can ignore it).
Similarly, it should be evident that as long as the amount of possible guesses is much larger than the amount of Nodes in a network, then the risk of two Nodes guessing the same GUID is very low and even negligible. To achieve this, we use a specific kind of function called a pseudorandom hash function to make our random guess.
A pseudorandom hash function is a function whose output is deterministic -that is to say it will always give the same output for a given input- but appears random. This means that if you were to show someone the output of a pseudorandom hash function, they should be unable to tell that the output is deterministic.
You can see pseudorandom hash functions as a kind of scrambler: such a function takes as an input a number and outputs something vastly different each time, such that each output seems unrelated to the previous one, appearing to be random.
At this point we have determined how to associate a unique address to each Node, but how can we communicate between these Nodes? For that we need to dive deeper into the way P2P networks exchange information.
Data Hashes
At its heart, the primary service a P2P network provides is a decentralized way to exchange information. But how can we locate this information?
If you want to find a book in a library, you refer to it's title, the author that wrote it, and perhaps even the publishing company: all sorts of unique information that make up the book's identity. A very inefficient way to search for a book would be to parse through every book in the library and look for one where every letter in it matches the expected value.
Similarly, if you want to access some data stored in a P2P network, you need some way of identifying that data. It would be inefficient to send large amounts of information over the network, so instead we rely on cryptographic hash functions.
A cryptographic hash function is a function which satisfies the following properties:
- Given any input it will return an output of fixed (usually small) length.
- The output of such a function should be deterministic.
- It should have a negligibly low probability of any collision occurring.
The input passed to a cryptographic hash function can be many things: a number, a very long text, or some other kind of information.
Let's break this down step by step.
-
First of all, the output of a cryptographic hash function is generally much smaller than it's input: in that way it allows us to shorten the identity of the data we are passing to it, similarly to how the title of a book and it's author provide a shorter identity when compared to the entire contents of the book itself.
-
Since this output is deterministic, this means that given the same input we will always get the same output from a cryptographic hash function. This is important since we want to use this output as a guarantee of identity: it would be inconvenient if that identity were to change each time we used it.
-
Finally, the probability of a collision occurring with a cryptographic hash function should be negligibly low. This is important because we do not want malicious actors to be able to create duplicate or false identities.
Among many other things, cryptographic hash functions can be seen as a guarantee of authenticity. They allow us to represent the identity of any kind of data in a short and concise way that is unique to that input.
Using a cryptographic hash function, we can generate unique identifiers for the information we want to store on our network. This is refereed to as hashing, which generates a unique identifier, or hash, for that information.
Now, if someone wants to access that information, they can generate its hash themselves and ask around the network until they find a Node which is storing that hash, at which point it will return the information associated with that hash.
We have essentially created a custom titling schema that allows us to easily retrieve the information which we store in our decentralized library of a P2P network.
Keyspace and Worldspace
So far we have seen:
- How to identify Nodes using a GUID based off a pseudorandom hash function.
- How to identify information stored on the network using data hashes generated with a cryptographic hash functions.
This presents a major discrepancy however: how do we handle GUIDs and the hashes of the information stored on our network (also referred to as keys)? We must begin by understanding two very important concepts: Worldspace and Keyspace.
Worldspace describes the set of all coordinates used to indicate the location of an object in the real, physical world.
Keyspace describes the set of all coordinates, or hashes, used to indicate a location in a P2P network.
It is important to note that while GUIDs describe Nodes which are located in the physical world (ie: Worldspace), the hashes or keys of the data in our network are being stored in Keyspace. In more mathematical terms, you can see Worldspace as the set of all possible GUIDs, while Keyspace is the set of all possible hashes.
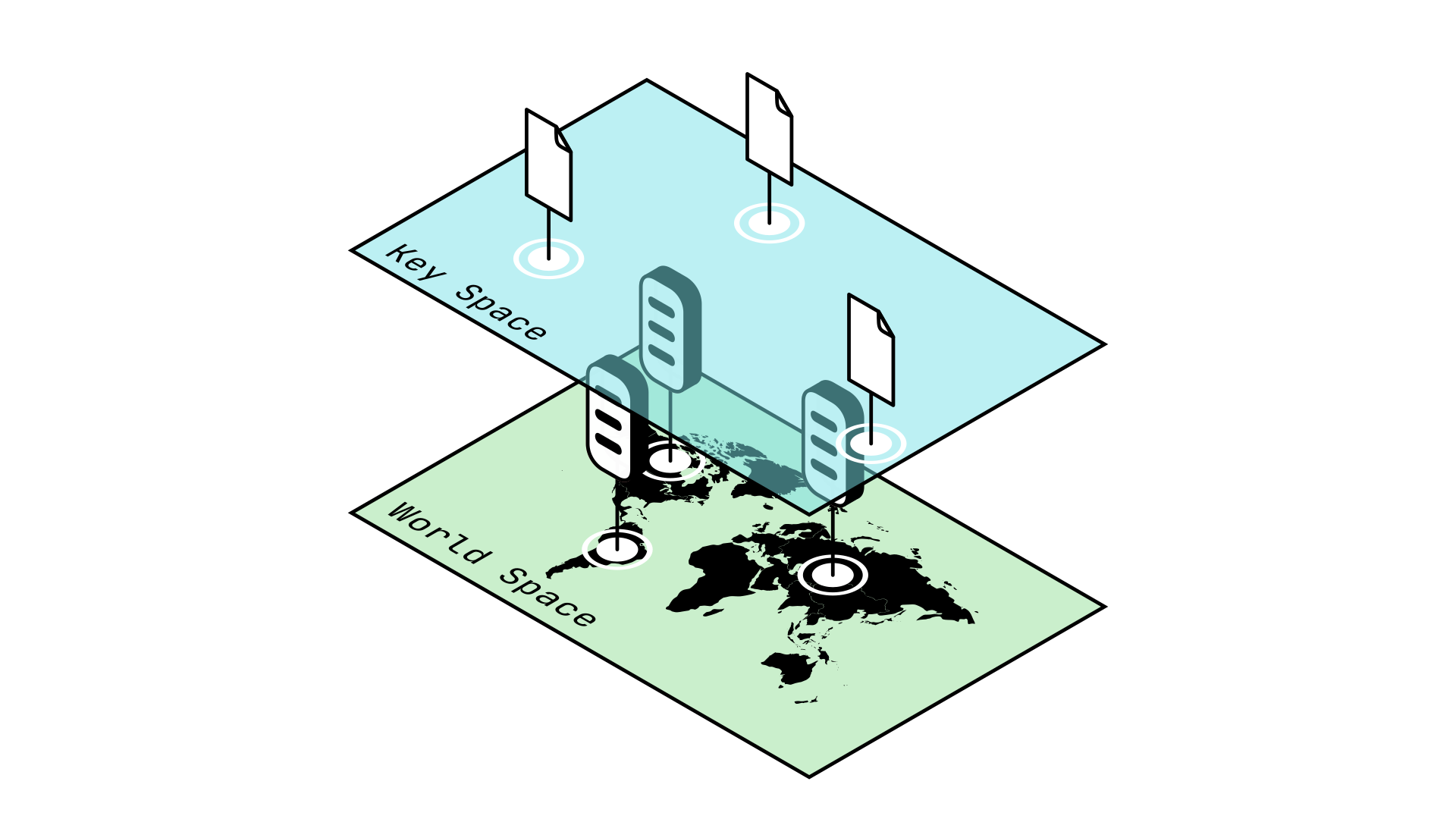
Fig. 1: Worldspace is incompatible with Keyspace
While this might not seem like an issue at first, consider that at the moment only the nodes themselves are aware of their own GUID. We will need a way to transmit GUIDs between nodes in the network, similarly to how we might request other data.
This becomes complicated if GUIDs are a different data type as compared to the hashes stored on the network in Keyspace, as this would require special treatment. Ideally, we would like GUIDs to be compatible with Keyspace, so we can treat them the same way as the data hashes already present.
You can think of this in the same way as vectors are incompatible with real numbers: it makes no sense to add a vector and a number together, and so we need special rules to interact between these two worlds. This makes our problems more complicated. Similarly to how it would be simpler if we could consider all real numbers as vectors, we would like for GUIDs and data hashes to be compatible.
Storing GUIDs in Keyspace proves very useful for other reasons, as it allows us to operate on GUIDs and data hashes together. For example, it allows us to define the distance between a Node's GUID and the data hashes around it, which proves essential to many P2P algorithms such as Kademlia.
In general, we would like to be able to reason about GUIDs and data hashes together, not separately.
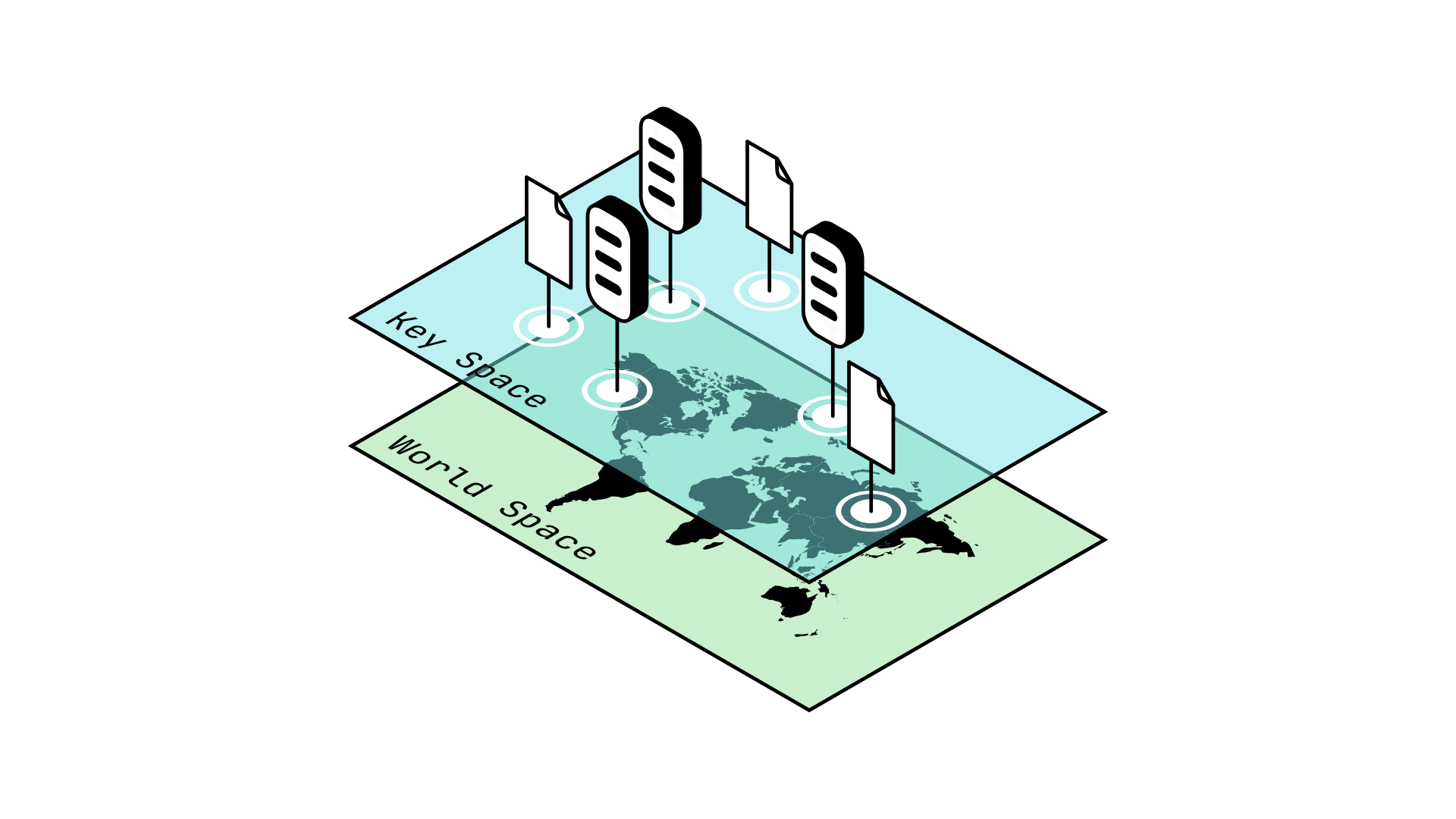
Fig. 2: Moving GUIDs to Keyspace allows us to operate on GUIDs and data hashes simultaneously
This is all very mathematical, so I will try and break it down into simpler terms:
-
The issue at hand is that we have two different data types: GUIDs, and data hashes. These data types are not necessarily compatible: GUIDs apply to objects in the real world, in Worldspace, while data hashes apply to information we store in a P2P network, in Keyspace.
-
Here, Worldspace can be seen as all the possible values of our pseudorandom hash function, and Keyspace as all the possible value of our cryptographic hash function. These can be very different, which makes them incompatible, like vectors and real numbers: this is an issue, as discussed before.
-
We want the cryptographic hash function we use to generate GUIDs to be compatible with the pseudorandom hash function used to generate data hashes. In the same ways that negative numbers are compatible with positive numbers, we want GUIDs to be compatible with data hashes.
This can be achieved by using the same function to generate both GUIDs and data hashes.
Benefits of Identity in P2P Networks
Establishing identity in a P2P network through GUIDs for Nodes and hashes for the data we store in our network allows for the easy and efficient exchange of information between Nodes, while the combination of GUIDs and data hashes into the same space allows for easy comparison and operations between the two.
These are the first steps in the algorithms which form the base of the many existing P2P protocols, so it is important you grow familiar with them: they will be instrumental in understanding the following sections on Chord and Kademlia.
Inter-Node communication with Chord
So far we have seen how to identify Nodes in a P2P network, yet it is still unclear how Nodes actually communicate between each other. There are many different ways that achieve this. Over the next two sections, we will be focusing on how the Chord and Kademlia algorithms can be used for this very purpose.
Since Kademlia is a modified version of Chord, we will only be exploring Chord in this context, in particular regarding how Nodes determine which other Nodes to connect to. We will therefore not be diving into a full explanation of the original Chord paper.
Discoverability
Given a network of arbitrary, growing size, we are trying to find a way to communicate efficiently from one end of the network to the other. Suppose we have a starting Node \(S\) and a destination Node \(D\): that means that starting from \(S\), we are trying to find the quickest viable path to \(D\). We can formulate the following constraints:
-
The path from \(S\) to \(D\) should be traversable in the smallest amount of steps, or network jumps. A network jump is when two Nodes connect to each other.
-
Finding this path should be very fast. There is no point in finding an optimal path if the time it takes to find it is much slower than the path itself.
-
Steps [1.] and [2.] should maintain the properties of decentralization of our P2P network. This means that we cannot rely on a centralized server which is responsible for keeping an overview of the state of the network.
Why is this hard? Can't we just directly connect our starting Node \(S\) to it's destination Node \(D\)? While that might be possible, it is not always the case. This is because there is no central entity keeping track of all the Nodes in the Network.
Importantly, it is not feasible for every Node to keep track of every other Node in the network, as this would mean that whenever a new Node enters the network it would have to update all other Nodes. The number of updates required for this to function grows linearly, making this approach not scalable, meaning it is not feasible at a large scale.
In a P2P network, each Node can only keep a partial map of the network at large, as keeping an up-to-date map of the entire network would grow too costly over time. Discoverability is the process by which Nodes use this partial map to connect to neighboring Nodes, which in turn try to get closer to the required destination.
Routing Tables
Due to constraints in keeping an up-to-date map of the network, Nodes can only keep track of a small set of neighbors. Chord (as far as we will see here) is an algorithm for determining which Nodes in the network make up these neighbors (hereafter referred to as peers). These peers are organized together into a routing table, which can be seen as a sort of imperfect map of the network that can then be used to try and get closer to the target destination.
\[\text{Given the following}\]
\(n := \text{node GUID}\)
\(N := \text{maximum number of nodes in the network}\)
\(m := \log_2(N), \text{ s.t } 2^{m} \ge N\)
\(m' := \text{number of peers in a routing table}, m' \lll m\)
\(k := \text{index of each peer in the routing table}, 0 \lt k \lt m'\)
\[\text{We define the } k^{th} \text{ peer in the routing table as:}\]
\[peer[k] = n + 2^{k-1} \mod 2^m\]
Let's break this down step by step:
-
Every Node in the network is keeping track of at most \(m'\) other peers. This value is chosen experimentally: the higher the value of \(m'\), the faster it will be for Nodes to communicate between each other, but the slower it will be for new Nodes to enter the network. A high value of \(m'\) also risks congesting the network by flooding it with too many messages.
-
Nodes keep as peers the Nodes which are closest to them in Keyspace. In fact, the distance between peers doubles each time. This means Nodes know more about the state of the network immediately around them, but are also able to connect to more distant Nodes if the destination is far away from them.
Essentially, this formula is creating a vague map of the network which mostly focuses on the local landscape, but with the mountains in the background in case it is ever needed to reach them. If you need more information, you can ask other Nodes along the way, as we will be seeing.
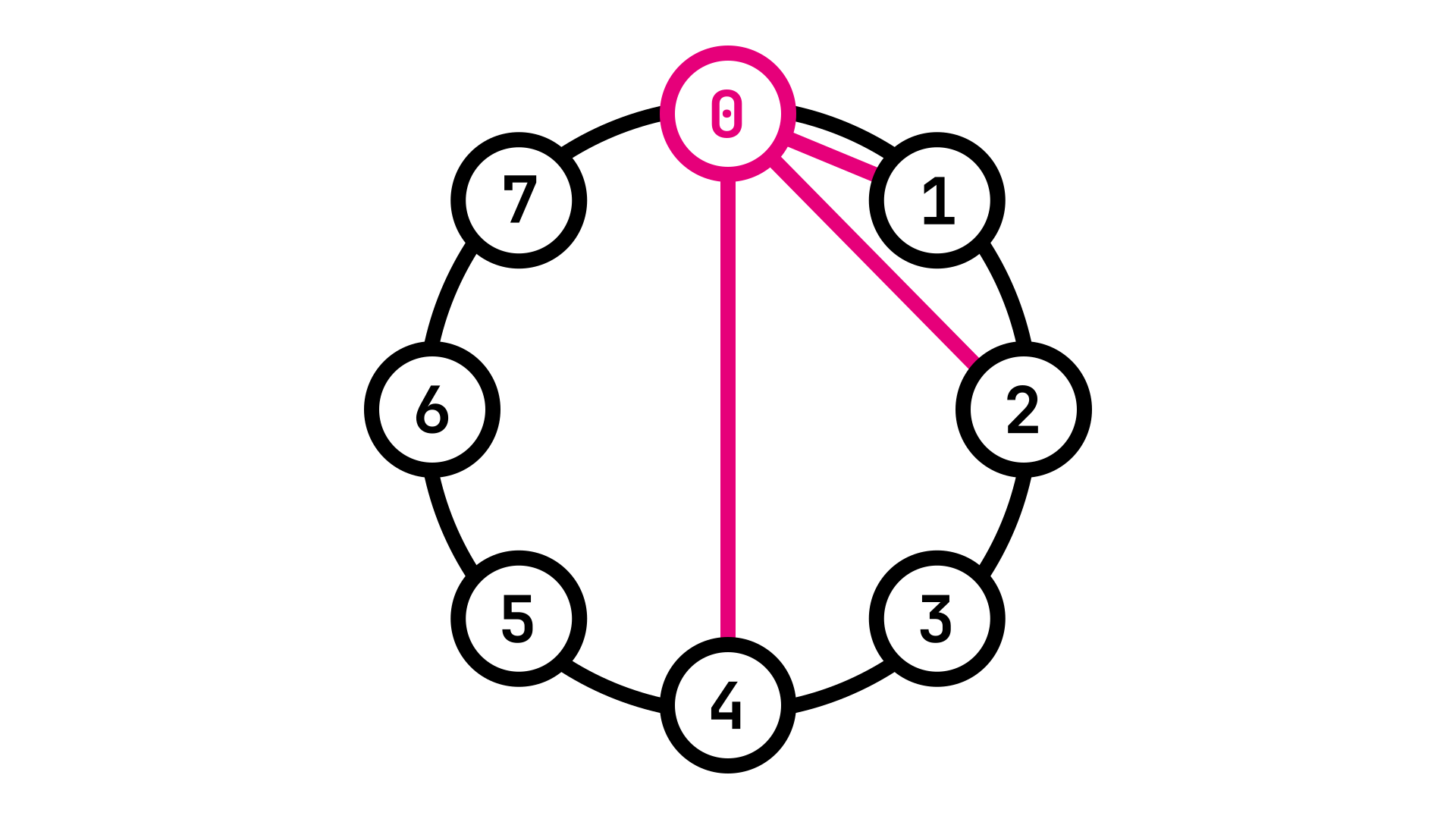 Fig. 1: Identifier circle showing the \(m\) peers of Node 0
Fig. 1: Identifier circle showing the \(m\) peers of Node 0
As we can see in Fig. 1, Node 0 is aware of Nodes 1, 2 and 4 as peers. It is not aware of any other Node in the network and cannot reach them directly.
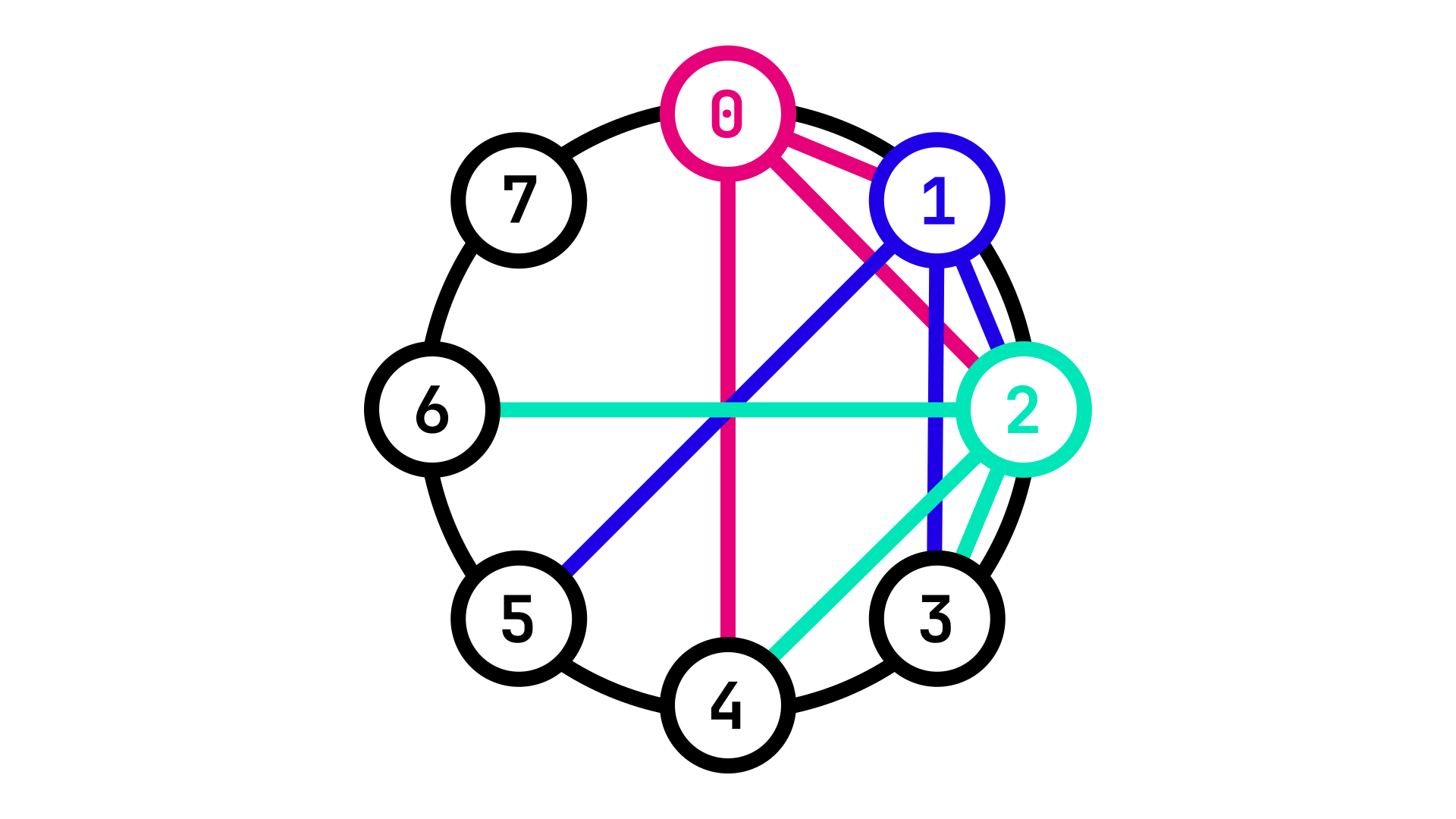
Fig. 2: Identifier circle showing the \(m\) peers of Nodes 0, 1 and 2
Fig. 2 expands this view by showing the peers of Nodes 0, 1 and 2. Notice how all together these Nodes can now connect to Nodes 0, 1, 2, 3, 4, 5 and 6 (we assume connections go both ways).
For a Node \(S\) to reach a target destination \(D\), we apply the following algorithm:
-
If \(D \in S\)'s routing table, then \(S\) can reach the target destination immediately.
-
If \(D \notin S\)'s routing table, then we perform a network jump to the next Node in \(S\)'s routing table which is closest to \(D\).
-
We repeat step [2.] until \(D\) is part of the routing table of the current node, at which point we can jump directly to it.
Using this algorithm, it can be proved that, starting at any node, it will take at most \(log(n)\) jumps to reach any other node in the network, where \(n\) is the total number of nodes in the network.
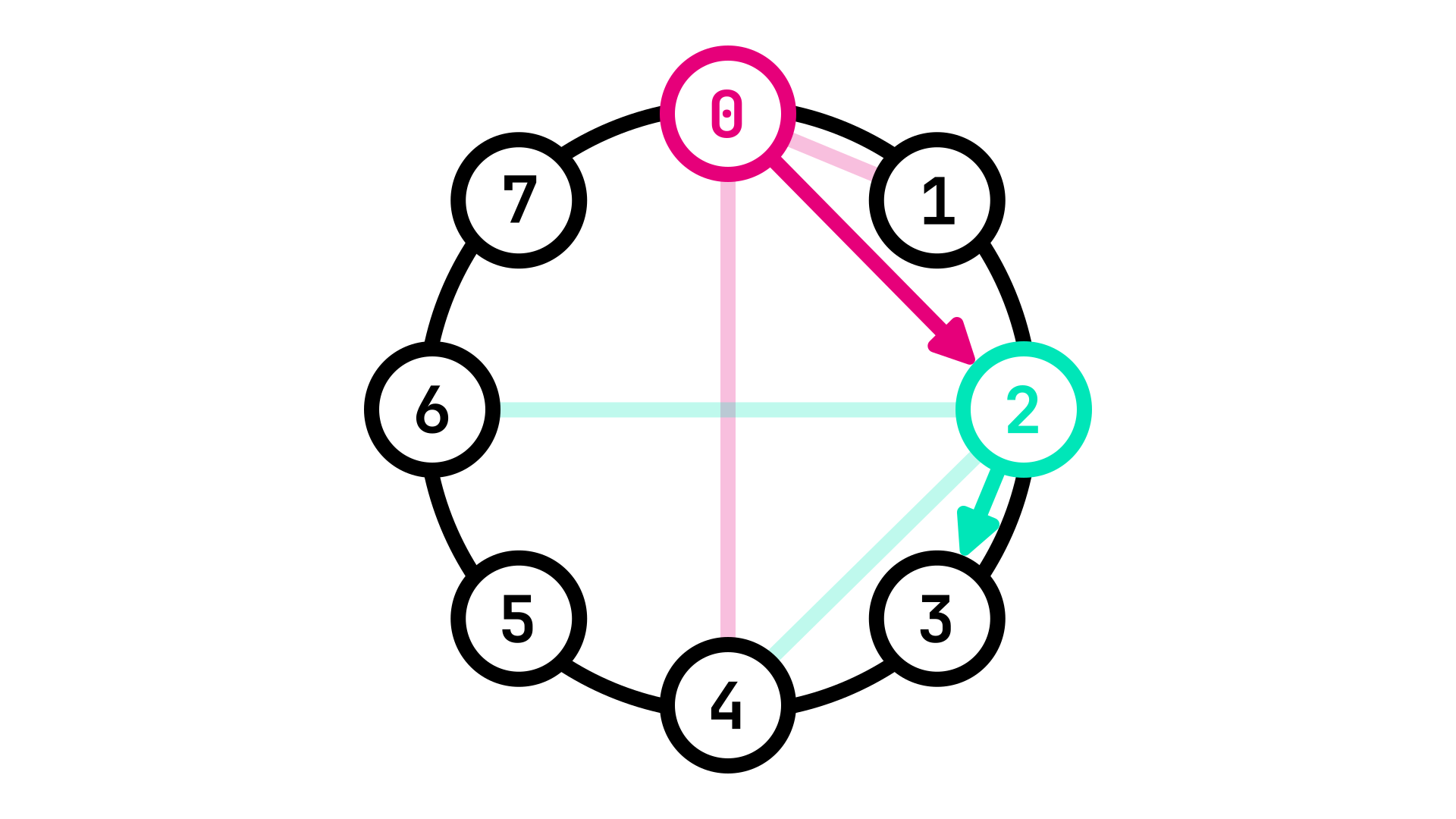 Fig. 3: Chord allows for efficient \(O(\log(n))\) traversal of the network
Fig. 3: Chord allows for efficient \(O(\log(n))\) traversal of the network
Fig. 3 illustrates a practical example of this algorithm:
-
Starting at Node 0, we want to reach Node 3.
-
Node 3 is not part of Node 0's peers, so we jump to the next closest Node in its routing table, Node 2.
-
Node 3 is part of Node 2's peers, so we can jump to it directly.
In this way, we were able to reach Node 3 starting at Node 0 in only 2 network jumps, even if Node 3 is not part of Node 0's peers.
Joining a P2P Network
So far we have seen how a Node can reach any target destination in the Network with only a limited routing table of peers. This however assumes a static network. How do we handle the case where new Nodes need to join? For this we need to introduce a new concept: Boot Nodes.
A Boot Node is a Node which is listed publicly (for example on the internet), to which new Nodes can connect for the first time.
This does not break the condition that no Node can have greater power over the network, as any Node can choose to become a Boot Node.
When a new Node \(N\) connects to a Boot Node \(B\) for the first time, it coppies \(B\)'s routing table. This is not ideal however, as \(B\) does not have the same GUID as \(N\), and so it's routing table will not match. \(N\) will then use this routing table to connect to other Nodes throughout the network and establish contact with its peers so as to create it's own routing table.
It is as if you started a journey with no map, so you go to the nearest stranger and ask him for a copy of theirs. It still isn't a perfect fit but it is a good starting point: you use it to go around and talk to other strangers and copy parts of their maps until you have the map that is best suited to your journey.
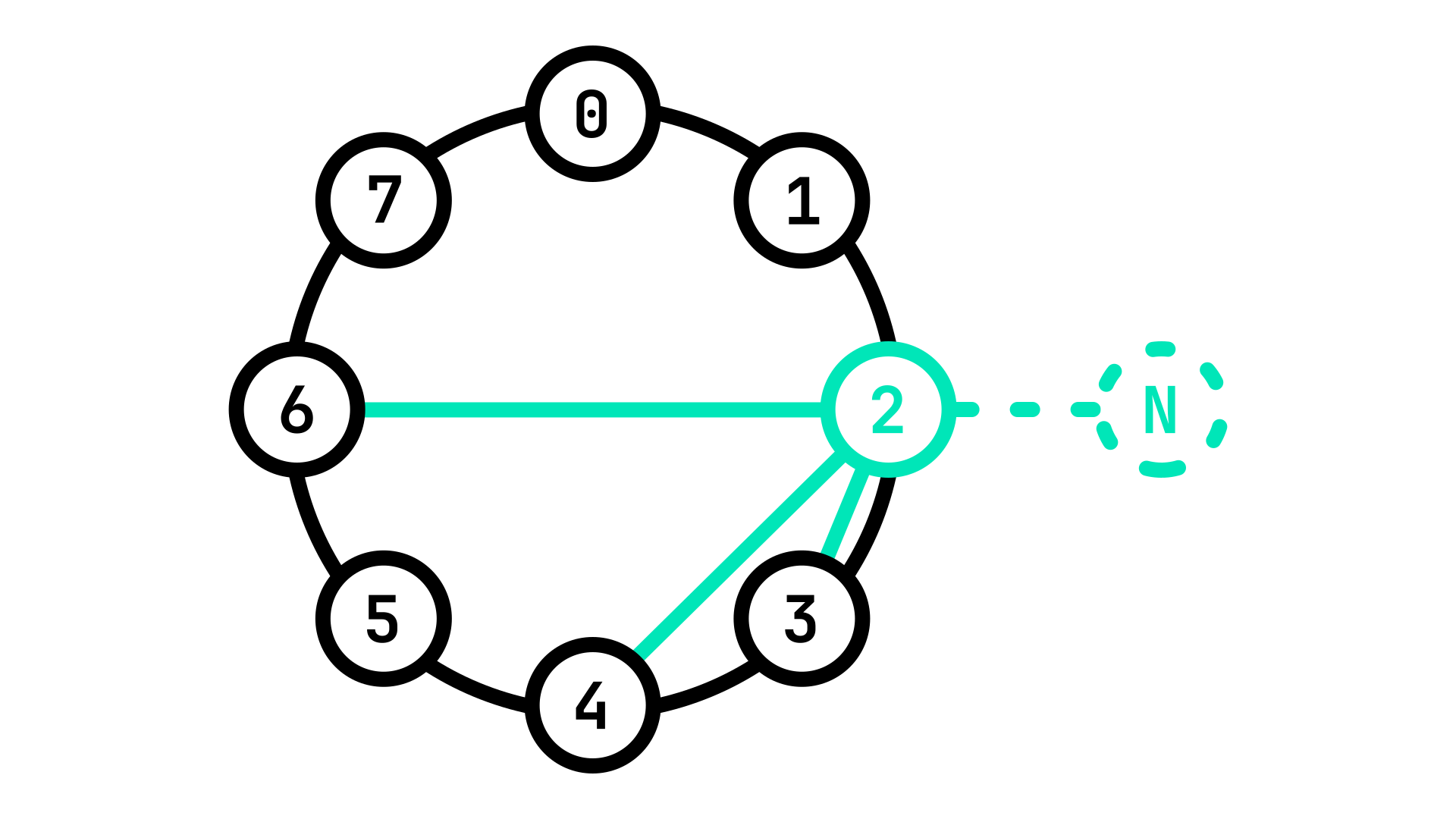 Fig. 4: A new Node \(N\) joining the network by connecting to a Boot Node
Fig. 4: A new Node \(N\) joining the network by connecting to a Boot Node
The actual process is a bit more involved, as it might result in updating the routing tables of other Nodes, but this will be discussed in greater details in the next section on Kademlia.